Les points abordés dans ce module :
- L’intelligence artificielle, concrètement c’est quoi ?
- Qu’est ce que le Machine-Learning ?
- Les réseaux de neurones artificiels, qu’est-ce que c’est ?
- Le deep learning, c’est quoi ?
1. L’intelligence artificielle, concrètement c’est quoi ?
🤖 Définissons le sujet
Pour mieux entrer dans le sujet, commençons par le définir.
Selon la Commission Nationale de l’informatique et des libertés (CNIL), l’intelligence artificielle est un « procédé logique et automatisé reposant généralement sur un algorithme et en mesure de réaliser des tâches bien définies.»
Le Parlement européen estime qu’il s’agit de tout outil utilisé par une machine afin de « reproduire des comportements liés aux humains, tels que le raisonnement, la planification et la créativité».
Alors, outil ? Procédé ? Tâchons de creuser plus en détail.
Concrètement, l’IA donne l’impression de « penser », dans le sens où elle ne se contente pas d’exécuter des ordres simples mais de planifier et résoudre des problèmes ou des tâches en faisant parfois preuve de «créativité» ou devrons-nous plutôt dire de «flexibilité» car l’IA ne repose que sur des règles logiques et fonctionne uniquement grâce aux programmes informatiques sur lesquels elle est basée.
Il faut alors éplucher l’IA, tel un oignon, pour comprendre les différents mécanismes qui la composent. Débutons par la première couche : le machine learning.
Comparaison du fonctionnement de l’IA à un oignon
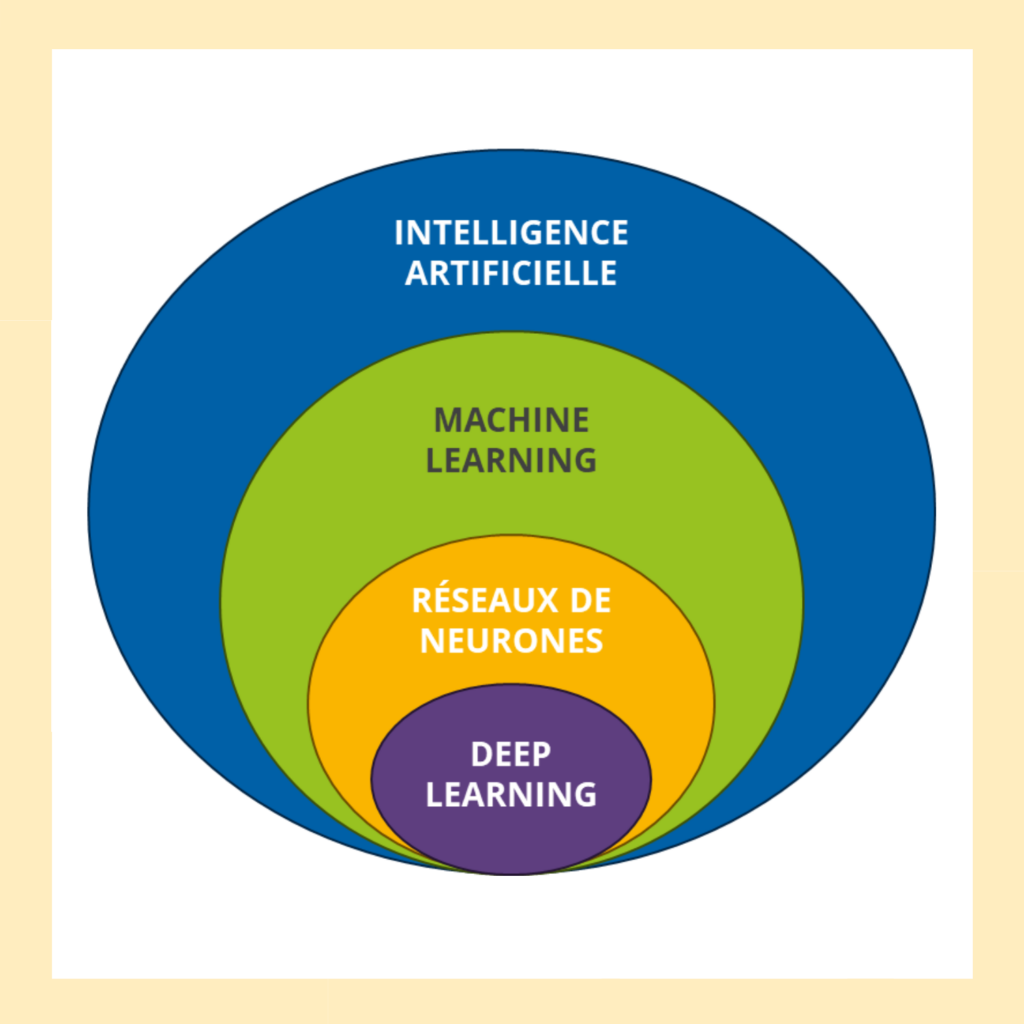
2. Qu’est ce que le Machine-Learning ?
🤖 Définissons le sujet
Le machine learning, ou apprentissage automatique en français, constitue la première strate technologique de l’intelligence artificielle. Concrètement, il s’agit d’une méthode qui permet aux machines d’apprendre par elles-mêmes à partir de données, sans qu’un développeur ait besoin de programmer manuellement chaque règle ou chaque scénario possible.
Pour bien saisir cette nuance, prenons un exemple simple. Dans la programmation classique, un développeur devrait explicitement écrire : “si l’email contient le mot ‘loterie’ et provient d’une adresse inconnue, alors c’est un spam”. Avec le machine learning, on montre au système des milliers d’emails préalablement identifiés comme spams ou non-spams, et l’algorithme découvre lui-même les patterns récurrents qui caractérisent un message indésirable. Cette capacité d’auto-apprentissage change radicalement la donne.
Le fonctionnement repose sur trois phases distinctes.
- D’abord, la collecte de données : des centaines, des milliers, parfois des millions d’exemples sont rassemblés.
- Ensuite vient l’entraînement : l’algorithme passe au crible ces données pour y détecter des motifs, des corrélations, des tendances.
- Enfin, la prédiction : une fois rodé, le système peut analyser de nouvelles données qu’il n’a jamais vues et prendre des décisions cohérentes.
Au-delà de la détection de spam, cette technologie infiltre désormais notre quotidien bien plus qu’on ne l’imagine. Lorsque Netflix vous suggère une série qui semble taillée sur mesure pour vos goûts, c’est du machine learning à l’œuvre. Le système a mémorisé ce que vous avez regardé, aimé, interrompu, et compare votre profil à des millions d’autres utilisateurs pour affiner ses recommandations. Plus vous utilisez la plateforme, plus l’algorithme cerne vos préférences. Cette même logique s’applique dans le e-commerce lorsque des articles vous sont suggérés.
Des technologies comme Google Maps, Waze ou CityMapper s’appuient également sur cette technologie pour prédire vos temps de trajet. L’application agrège les données de millions de conducteurs en temps réel, apprend quels axes sont généralement saturés à telle ou telle heure, et peut ainsi anticiper votre heure d’arrivée avec précision. Le secteur médical tire aussi profit de ces avancées. Certains algorithmes, entraînés sur des dizaines de milliers de radiographies, permettent de détecter des signes de cancer ou d’anomalies.
Ces exemples permettent de mieux visualiser ce qu’est le machine learning, qui demeure l’une des couches les plus concrètes de l’intelligence artificielle. Mais, pour établir de telles connexions, le machine learning s’appuie sur une architecture particulière : les réseaux de neurones artificiels.
3. Les réseaux de neurones artificiels, qu’est-ce que c’est ?
🧠… Un cerveau numérique : pas exactement
Comme leur nom l’indique, les réseaux de neurones artificiels s’inspirent directement du fonctionnement biologique du cerveau humain, bien qu’ils en constituent une version considérablement simplifiée.
Concrètement, un réseau de neurones se compose de plusieurs couches de “neurones” interconnectés. Chaque neurone reçoit des informations, les traite, puis transmet le résultat aux neurones de la couche suivante. Cette organisation en strates permet de décomposer un problème complexe en une succession d’étapes de traitement de plus en plus abstraite. Le principe reste relativement simple à visualiser, il suffit d’imaginer une chaîne de production où chaque ouvrier effectue une tâche précise avant de passer au produit suivant.
Représentation d’un réseau de neurones
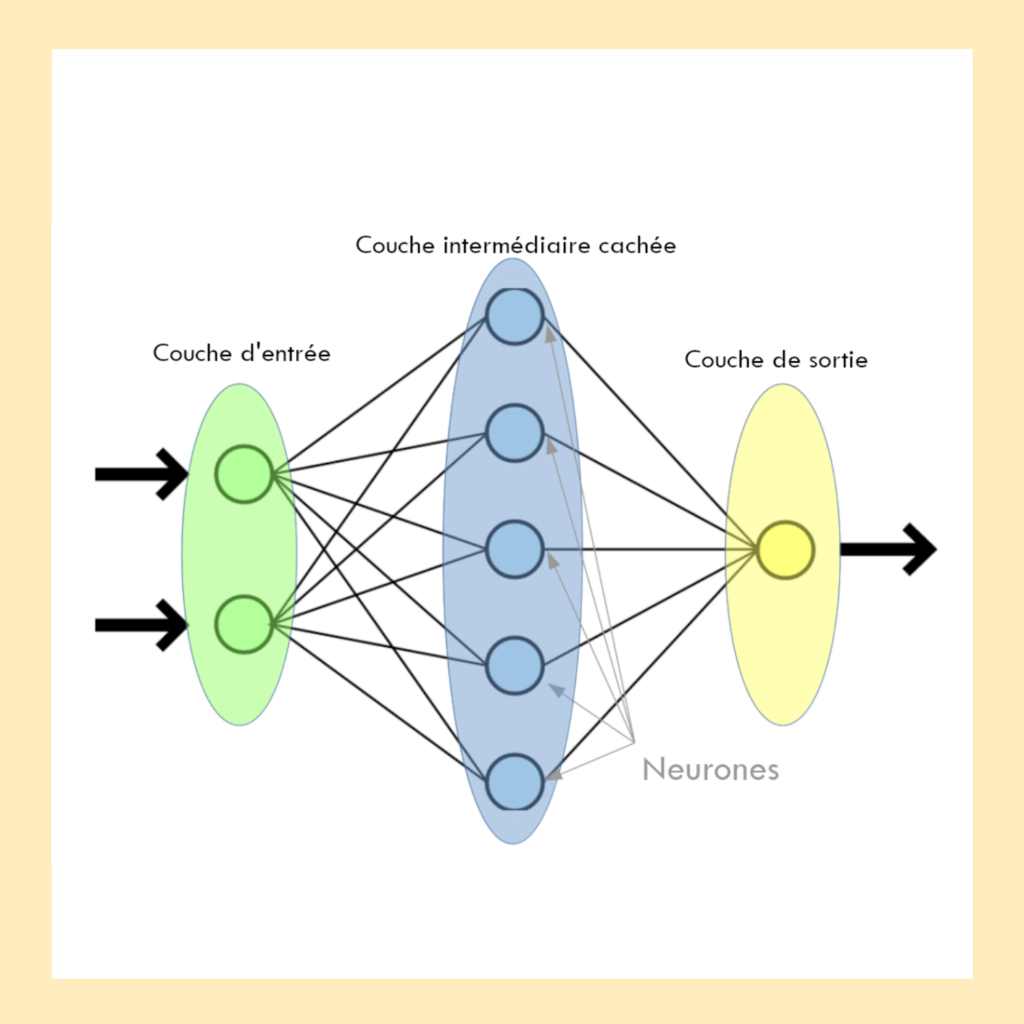
La première couche, dite “d’entrée”, reçoit les données brutes ; une image, un son, du texte etc. Les couches intermédiaires, appelées “cachées”, extraient progressivement des caractéristiques de plus en plus sophistiquées. Enfin, la couche de sortie produit le résultat final : “cette image représente un chat”, “cet email est un spam”, ou encore “ce patient présente des signes de maladie”.
Chaque lien entre deux neurones possède un poids, qui traduit l’importance de l’information transmise. Lors de l’apprentissage, le réseau qui reçoit un grand nombre d’exemples essaie d’en déduire des modèles ou des régularités. Quand il se trompe dans ses prédictions, un algorithme ajuste légèrement ces poids afin de réduire l’erreur lors des essais suivants. Ce processus, appelé rétropropagation, consiste à faire circuler l’erreur en sens inverse dans le réseau pour corriger les connexions responsables. Progressivement, ces ajustements permettent au modèle d’améliorer sa compréhension du problème et de produire des résultats plus précis.
❌️Les limites d’un réseau de neurones artificiels
Cette architecture se révèle particulièrement efficace pour des tâches que les humains réalisent instinctivement mais qu’il serait quasi impossible de programmer manuellement. Reconnaître un visage dans une foule, comprendre une phrase ambiguë… autant de défis qui requièrent de saisir des nuances subtiles plutôt que d’appliquer des règles rigides.
Un exemple concret dans notre quotidien ? La reconnaissance faciale, omniprésente sur nos smartphones, repose sur cette technologie. Lorsque vous déverrouillez votre téléphone d’un simple regard, un réseau de neurones compare instantanément les caractéristiques de votre visage: distance entre les yeux, forme du nez, contour des lèvres, à un modèle préalablement enregistré. Le système tolère les variations de luminosité, d’angle ou même de légères modifications de votre apparence, comme des lunettes ou une barbe naissante.
Malheureusement, cette puissance a un coût. Les réseaux de neurones nécessitent des quantités massives de données d’entraînement et une puissance de calcul considérable. Là où un algorithme classique peut tourner sur un ordinateur portable, certains réseaux sophistiqués requièrent des fermes de serveurs équipés de processeurs spécialisés pendant des jours, voire des semaines. Mais c’est une problématique que nous aurons l’occasion de développer plus tard dans ce module notamment sur les risques environnementaux liés à son fonctionnement (cf. Module 2.5 : 4. Les enjeux environnementaux).
4. Le deep learning, c’est quoi ?
🤖 Définissons le sujet
Si les réseaux de neurones constituent l’architecture de base,le deep learning (ou apprentissage profond en français) pousse cette logique à son paroxysme. Cette technique ne diffère pas fondamentalement des réseaux de neurones classiques, mais elle repose sur des architectures bien plus complexes, comportant des dizaines, voire des centaines de couches de neurones superposées. Voyez donc le deep learning comme une sous-catégorie du machine learning dotée d’une profondeur qui lui confère des capacités inédites.
Là où un réseau de neurones simple possède généralement trois ou quatre couches, une d’entrée, une ou deux cachées, puis une de sortie, un modèle de deep learning en aligne parfois plus d’une centaine. Chaque couche supplémentaire permet d’extraire des représentations de plus en plus abstraites et sophistiquées des données. Les premières couches détectent des éléments basiques comme des contours, des formes géométriques simples, des variations de luminosité. Les couches intermédiaires combinent ensuite ces éléments pour reconnaître des structures plus élaborées comme des textures, des motifs récurrents, des compositions. Les couches finales synthétisent l’ensemble pour identifier des concepts de haut niveau comme un visage, une voiture, un chat.
Cette hiérarchisation du traitement imite le fonctionnement du cortex visuel humain. Lorsque vous regardez une photographie, votre cerveau ne perçoit pas instantanément “une personne debout près d’un arbre”. Il décompose d’abord l’image en éléments rudimentaires puis les agrège progressivement jusqu’à reconnaître des objets cohérents. Pour résumer, le deep learning reproduit ce mécanisme de manière artificielle.
✳️Ce que permet le marchine learning
Cette approche multicouche permet à la machine d’apprendre automatiquement les bonnes caractéristiques à extraire des données, sans intervention humaine. Dans le machine learning classique, un ingénieur doit identifier manuellement les paramètres pertinents comme la forme d’une oreille pour distinguer un chat d’un chien, la fréquence de certains mots pour détecter un spam. Avec le deep learning, le système découvre lui-même ces critères distinctifs. On lui montre des milliers d’images étiquetées “chat” et “chien”, et il détermine quels indices visuels sont les plus discriminants.
Les chatbots conversationnels les plus avancés comme ChatGPT, Claude ou Gemini constituent probablement l’application la plus emblématique du deep learning. Pour comprendre vos questions et y répondre de manière cohérente, ces modèles ont ingéré des quantités astronomiques de texte provenant d’internet, de livres, d’articles scientifiques. Ils ont appris les structures grammaticales, le vocabulaire, les raisonnements logiques, jusqu’à pouvoir produire des réponses articulées et contextuellement pertinentes sur pratiquement n’importe quel sujet.
🖼️Le cas du rôle de l’IA générative dans le domaine artistique
Le secteur de la création artistique s’est également emparé de cette technologie. Des modèles génératifs comme DALL-E, Midjourney ou Sora produisent des images photoréalistes ou stylisées à partir de simples descriptions textuelles. Vous tapez “un chat astronaute flottant dans l’espace, style peinture à l’huile”, et l’algorithme génère en quelques secondes une illustration correspondant précisément à cette demande. Ces systèmes ont assimilé les corrélations entre des millions de paires texte-image, apprenant ainsi les codes visuels associés à chaque concept.
Ces derniers exemples représentent l’utilisation majoritaire de l’IA par le grand public. Une catégorie appelée IA générative, à laquelle on réduit souvent, à tort, l’intelligence artificielle.
Ce module a été rédigé par Hugo Lausenaz-Pire, consultant en gestion des risques et conformité de cybersécurité chez Advens, passionné par l'intelligence artificielle et diplômé en Mastère expert informatique et système d'information spécialité sécurité IT.